Using AI and ML in Smartphones: Today and in the Future
A wide range of AI and ML performance is required by use cases on smartphones now and in the future. The goal is to deliver required performance with the highest levels of efficiency, in the smallest area and at the lowest cost. This can be made possible by heterogeneous AI across the CPU, GPU, and NPU and then optimized through the software.
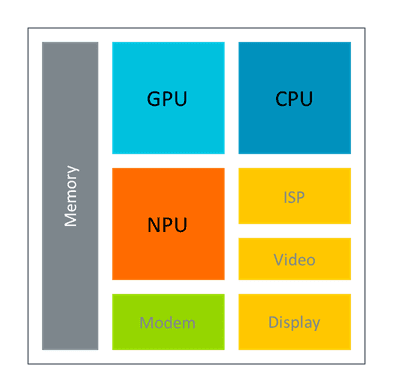
AI and ML workloads in a current smartphone system-on-chip (SoC) are handled by the blocks in the diagram below.
It is essential to closely couple the application with AI and ML acceleration, allowing low-latency/fine-grained interactions, and minimizing the movement of data throughput, keeping it local, whenever possible.
Each processing block has specific strengths and a role in meeting the overall system efficiency goal. This is supported by a range of software development tools and optimizations to accelerate SoC designs and enable developers to write easier, simple, more secure and faster software for Arm-based mobile devices.
The CPU is flexible and ubiquitous across mobile computing. In the smartphone space alone. Arm is the most pervasive CPU architecture in the world with 99 percent of all smartphones built on Arm.
The latest Armv9 CPUs feature SIMD and vector extensions (NEON, SVE2, SME) that are built into the latest Armv9 architecture to optimize AI and ML workloads. The CPU Cluster for Arm CSS for Client includes the Cortex-X925, Cortex-A725, and Cortex-A520, and delivers 172 percent faster AI performance, compared to the Arm TCS23 reference CPU Cluster.
GPU technology is perfectly suited for high-speed data processing, and parallel computations, which are a staple for AI, ML, and neural networks. This is made possible by the following features and capabilities:
Parallel data processing architecture.
High-throughput compute platform.
Ability to transform rendering efficiency and quality through enabling super-sampling and ray denoising.
An ML platform for third-party developers through the ability to integrate with key middleware and game engines.
Support for the Vulkan API, which is used to develop and optimize gaming and graphic intensive applications.
The GPU is frequently used by applications to accelerate neural networks, as there are many other compute workloads that use the GPU and benefit from AI and ML acceleration. Examples include third-party camera/vision applications and video editing/creation applications, as these have very similar properties to neural graphics workloads.
Arm remains committed to developing and testing our GPUs against new applications for AI and ML. One key ML use case is 3D scene reconstruction, which renders novel views of real-world scenes on the mobile GPU. Exploring this particular use case, we have seen the Arm Immortalis-G720 GPU achieve 25 percent more peak performance and consume 22 percent less memory bandwidth compared with Immortalis-G715.
Plus, when combining these hardware improvements with further software optimizations through Arm NN (Arm's ML inference engine) and Arm Compute Library (Arm’s ML software libraries), Immortalis-G720 provides four times the ML performance boost on a super resolution FSRCNN network.
The new Immortalis-G925 brings even more performance, with 36 percent faster inference of AI and ML networks, compared to Immortalis-G720.
Overall, thanks to Arm CPU and GPU performance improvements, AI processing capability has roughly doubled every two years.
Standalone NPUs are usually suitable for flagship and premium devices where the additional die area and SoC cost is not such an issue. They work seamlessly with Arm CPU and GPU processors, and are typically used for image and video enhancement including the following use cases:
Face and object recognition
Noise reduction and low-light photography
HDR and artificial bokeh
Region-of-interest selection, optimization, and tracking
NPUs use proprietary APIs and are closely coupled in hardware, for example, with the image signal processor (ISP), video, and display processors. They are dedicated to built-in first-party applications on the mobile device, and therefore can be difficult to use with third-party applications running on the CPU or GPU, due to data bandwidth and latency issues.
Alongside enabling more capable hardware for AI and ML workloads, Arm is investing in software improvements to power future AI- and ML-based experiences on smartphones. Arm has made the Arm NN software development kit for AI and ML-based applications available across the ecosystem. Arm NN has been deployed on over 1.7 billion devices (and growing).
Arm NN and Arm Compute Library, which is a wide set of highly tuned ML functions, provide best-in-class performance for AI and ML on Arm. Since 2023, Arm NN and the Arm Compute library have been used by Google Apps on Android, with over 100 million active users already. Soon these Arm software libraries are going to be made accessible to third-party applications via Google Play Services for Android developers. This means every Android developer can access the latest the Arm technologies and software updates, ensuring best-in-class AI performance on Arm.
The first part of new Arm Kleidi software is the Arm Kleidi Libraries for popular AI frameworks, which feature KleidiAI for unleashing CPU performance across AI workloads and KleidiCV for accelerating computer vision (CV) workloads. By using the Kleidi Libraries, developers can accelerate AI without requiring extra effort, while enabling the faster and smoother execution of AI and CV models on Arm-based devices.
KleidiAI, our response to the surge in device types, neural networks, and inference engines, is a suite of highly optimized, lightweight AI kernels. These kernels excel in various use cases, including generative AI, by integrating seamlessly with popular AI frameworks such as MediaPipe, Llama.cpp, PyTorch, and TensorFlow Lite.
Through working with Google AI Edge, Arm successfully integrated KleidiAI into the MediaPipe framework. This integration, which is accelerated on the Arm CPU via XNNPACK, an open-source library of highly optimized neural network operators, supports a wide range of LLMs, including the Gemma 2B LLM.
These efforts have led to a significant 30 percent increase in performance in time-to-first token, which relates to how many tokens are being processed per second. In this instance, the KleidiAI integration enabled 250 tokens to be processed in one second for a more responsive experience, with this being observed via Arm’s chatbot summarization demo on the Gemma 2B LLM on Samsung’s Galaxy S24 smartphone (Exynos 2400), which is powered by Arm CPU technologies.
These promising results have far-reaching implications for AI developers when running their own AI workloads. Moreover, the great performance shows what is possible for LLMs on the CPU, and how this can enable many real-world AI inference use cases, including chatbot, smart reply and message summarization.
We are now at the point where the mobile ecosystem has realized that a broad range of computing and development challenges can be addressed by AI and ML. However, in order to reach their full potential, AI and ML-based technologies must be accessible to a broader audience of developers and addressable within the frameworks in which they operate.
That is why we are working directly with leading AI frameworks, including MediaPipe (via XNNPACK), LLAMA.cpp, PyTorch (via ExecuTorch) and TensorFlow Lite (via XNNPACK), to integrate KleidiAI.
Another challenge is that AI and ML are currently bound up in vendor-specific approaches, which can be a hinderance to wider innovation. Industry standards serve to both democratize and reduce overall costs associated with development, deployment, and maintenance that would otherwise be prohibitive.
For developers, API integration is a crucial element of a deployment platform. Arm sees Vulkan extensions as the way forward. These provide developers with a state-of-the art solution that aligns as closely as possible with current compute shaders.
Under the hood, these shaders have an intermediate representation in Vulkan that is known as “SPIR-V.” In defining an ML extension for developers, an analogous intermediate representation is required. For this purpose, we view the Tensor Operator Set Architecture (TOSA) as a fitting solution.
Developers also need industry standards like Vulkan, to reduce fragmentation cost and enable effective deployment paths.
As we imagine the evolution of AI and ML workloads, their future acceleration should be close to wherever the application needs it. For the broad range of use cases, this requires a fine balance between computational efficiency, latency, and power consumption. CPU-based AI and ML is a natural fit for low latency, ‘run-everywhere’ workloads. Meanwhile, GPU-based AI and ML are a natural fit for traditional GPU workloads, such as gaming, computational photography, and video.
As discussed previously, there are a wide range of use cases where AI and ML enhance mobile gaming applications, from better gameplay through to higher-fidelity 3D graphics, through to neural ray denoising. Leveraging AI and ML to bring these enhanced capabilities to game studios and their games requires investment, with new techniques to understand, tools to learn, and workflows to practice. Developers will rightly be asking if this level of investment in time and costs is worthwhile, but there is significant potential to increase the return on investment (ROI) in their games through each AI-enhanced feature.
To tip the balance, Arm believes that ease of adoption when incorporating these new AI-based enhancements into titles is absolutely essential for developers, as it reduces time and cost during the game development process to help maximize ROI. A range of measures is needed, from simple turn-key solutions for titles with constrained budgets to fully customizable neural network kits for those AAA gaming titles where developers want to differentiate through neural networks.
This also means supporting the most popular and common ML frameworks and toolkits used by developers to train neural networks. Frameworks from PyTorch and JAX must work first time on mobile with the right level of support throughout the application development process. Developers also need “desktop-class” tooling that they use daily, like debugging and profiling tools, that provide relevant and detailed insights into how their AI and ML workloads are performing. Time to market is everything for developers, so broken tools cannot delay the application development process.
Putting developers first is key to enabling (and leading) the mobile ecosystem successfully. Therefore, being able to seamlessly develop applications with easily accessible AI and ML on Arm through our CPUs and GPUs, as well as the most commonly used ML frameworks and toolkits, is a crucial part of accelerating AI- and ML-based experiences and use cases on mobile, both now and in the future.
Arm CSS for Client sets the benchmark in performance efficiency with Armv9.2, featuring physical implementations and ongoing software optimizations. This combination is set to revolutionize experiences for both developers and consumers. The CSS journey continues next year, promising exciting advancements and significant performance gains in both CPU and GPU.
Arm is delivering mobile innovation from silicon to software that supports bringing increasingly immersive digital experiences to life by our vast global ecosystem. AI and ML workloads are core parts of these immersive digital experiences. They deliver significant advancements in the mobile experience, particularly mobile gaming, through stunning graphics and visual experiences for users.
AI and ML are happening on Arm, with Arm technologies providing the hardware and software capabilities to define AI-based mobile experiences. From our leading CPU and GPU technologies to the development tools that allow developers to create AI and ML applications for Arm-based mobile devices, AI and ML on graphics for mobile are making significant strides on Arm.