The Third of Six Key Challenges
AI systems are increasingly trained on highly sensitive personal data, both in centralized data lakes, as well as on edge devices. Many modern machine learning techniques rely on access to large data sets. The more data that the data set contains, and the more attributes that each record in the data set possesses, the more useful a data set tends to be for machine learning purposes.
These data sets pose a privacy hazard, both during the machine learning training phase when sensitive data is pooled together — potentially on an untrusted device — and during inference, when a trained machine learning model can be “probed” by a malefactor to infer information about the data set used to train the model.
What are the latest state-of-the-art technologies and best practices that can balance the tension between context-relevant personalization and society’s concerns about mass surveillance and secondary use?
There are several ways to address the privacy hazards associated with large data sets. One approach is to modify the data set or limit the types of questions that can be asked about the underlying data in the data set, using anonymization techniques.
4.3.1 Anonymization
Naïve Data Anonymization
Data sets can be anonymized naïvely by removing attributes that appear to be particularly sensitive – such as names, addresses, dates of birth, and so on. However, several kinds of privacy attacks can be used to reconstruct or de-anonymize data that were manipulated using careless anonymization techniques:
Linkage Attacks can be used to link records in an anonymized data set with records appearing in a public data set. These attacks can be surprisingly powerful: in one infamous example, a linkage attack was used to reveal the Governor of Massachusetts’ health records after an anonymized medical data set was linked against freely available voter registration data.16 In addition, background knowledge can also be used to de-anonymize data. Knowing that heart attacks occur at a reduced rate in Japanese patients, compared to other nationalities, could be used to narrow the range of values of an attribute in medical data sets.17
Differencing Attacks use carefully constructed sets of complementary queries over data sets – even very large ones – to infer the attributes of private records. By issuing the complementary pair of queries, “How many people in this database are known to have cancer?” and, “How many people in this database, not named John Smith, have cancer?” an attacker can infer information about the health of John Smith without having to directly query for that information.
Query Auditing Techniques
Query auditing techniques use explicit checks on data queries to try to gauge if the results of those queries can cause a privacy breach, before being applied to the data set. If a query can cause a privacy breach, it is blocked. Query auditing techniques would appear to be a good first defense against certain types of differencing attack.
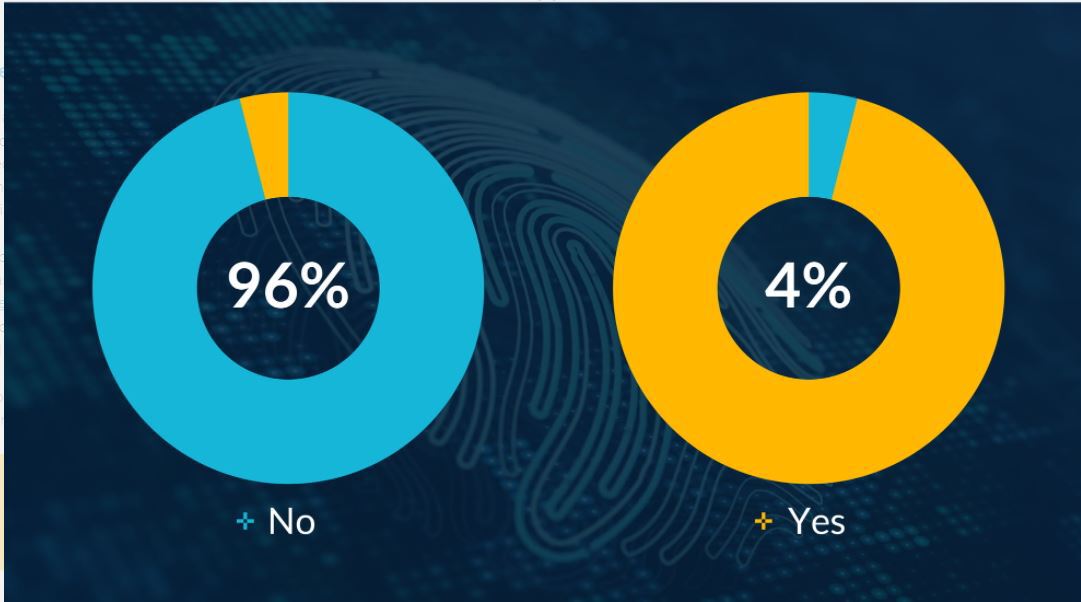
Lacking Confidence: only 4% of organizations are completely confident in their security policy when it comes to protecting third-party data. Source: Arm/Pulse 2021.
Unfortunately, this is not the case, as refusing to process a query in the context of a series of previous queries may itself reveal sensitive information about the underlying data set. Moreover, depending on the expressiveness of the underlying query language, detecting a potential breach of privacy from a series of queries may not even be computationally feasible.
Given the problems with naïve data anonymization, computer scientists have sought to give a precise definition of data privacy and an associated framework within which informative queries over data sets can be made without necessarily sacrificing privacy.
k-Anonymity
Early attempts at providing a framework within which data privacy could be evaluated, such as k-anonymity18 – and its many refinements such as t-closeness19 and l-diversity20 – focused on formalizing the naïve idea of anonymizing a data set by removing record attributes, as discussed above.
Intuitively speaking, a data set has the k-anonymity property – where k is a privacy parameter – if the record of any one individual appearing in the data set cannot be distinguished from the records of any other k – 1 individuals also appearing in the data set. This property, therefore, entails that any one individual in the data set has a form of “plausible deniability” with respect to the results of queries over the data set.
Data sets can be manipulated by removing attributes, or making the range of values that an attribute can take on to be less precise, so that it eventually satisfies the k-anonymity property for some desired privacy parameter, k. Unfortunately, k-anonymity and variants are still subject to a range of privacy attacks.
Differential Privacy
Differential privacy’s modern form21 was perfected by cryptographers and makes use of a modified form of a central concept in the theory of cryptography: indistinguishability.22 Whereas techniques such as k-anonymity try to protect sensitive data by manipulating a data set, differential privacy focuses on the queries, or generalized ‘algorithms’ that can be made about, or computed over, a data set.
The central observation behind differential privacy is inherently intuitive: an individual’s privacy cannot be compromised by an inadvertent release of data from a data set if that data set does not contain any data related to that individual. As a result, a query over a data set is differentially private if it is indistinguishable to an external observer whether the query was computed over a data set containing an individual’s data, or over a data set with the data removed.
Indistinguishability is achieved by adding carefully chosen random noise to the output of a query. Naturally, the amount of noise to add to the output of a query is a function of the data set itself. For example, if a data set contains information about only a single person, then the amount of statistical noise needed to achieve this indistinguishability property is necessarily much greater than is needed to mask the inclusion or exclusion of an individual’s data in a query over a data set containing data about all 500 million Europeans.
Differential privacy is now routinely deployed as a means of guaranteeing the privacy of individuals appearing in large data sets. For example, both Apple23 and Microsoft24 use variants of differential privacy to anonymize telemetry information originating from devices running their operating systems, and the US Census Bureau also uses differential privacy when aggregating population-wide statistics.25
However, despite real-world deployment, differential privacy is not a panacea and does not guarantee perfect privacy, but merely places an upper bound on the amount of information that leaks from a query over a data set. Moreover, significant amounts of noise may be required to obtain the indistinguishability property, making differential privacy inappropriate for some uses.
4.3.2 Federated Learning
An alternative approach to addressing the privacy hazards associated with large machine learning data sets is to avoid collecting large pools of potentially sensitive data in one centralized data set. Federated learning26 is a distributed technique wherein a collection of nodes – for example, mobile phones, tablets, or edge devices – each possessing their own private data set, co-operate to build a combined machine learning model without explicitly exchanging records from their private data sets. Instead, each node trains a local model, which are then combined, either by a central server, or in a decentralized fashion, to produce an aggregate machine learning model.
Note that this aggregate model is obtained without any private data set ever leaving that node.
4.3.3. Cryptographic Techniques
Several cryptographic techniques can be used to guard privacy. Homomorphic encryption schemes allow computation to take place directly on encrypted ciphertexts, without requiring the data to first be decrypted. Using this technique, encrypted data can be freely shared with untrusted third parties for processing without sharing the data itself, or the results of the data processing thereafter.
In a machine learning context, private data originating from a device can be encrypted and transmitted to a central server, where inference takes place using pre-trained models. The result is then transmitted back to the originating device without any private data being revealed.
Secure multiparty computations27 allow a group of distrusting individuals to jointly compute a function over their private data sets, without revealing those data sets to each other. Many protocols for collaborative, privacy-preserving machine learning have been developed by cryptographers.28
Arm Chief Architect Richard Grisentwaite outlines the future of security with technologies such as trusted execution environments..
4.3.4 Hardware-Based Trusted Execution Environments
Hardware-based trusted execution environments (or TEEs) can be used to build systems that address many of the same use cases as the cryptographic techniques that we surveyed above: namely, the protection of data while in use, and when it is pooled amongst a group of mistrusting individuals as a means of computing a joint function over that combined data.
Naturally, the use of TEEs for this purpose has both disadvantages and advantages. To deploy software within a TEE, the user needs to first establish that the TEE is trustworthy. This typically involves an attestation protocol, which is used to verify the provenance of the hardware platform, and supporting firmware, that need to be trusted for the TEE to meet its security guarantees. The hardware, firmware, and attestation protocol need to be explicitly trusted to enable use of TEEs.
By contrast, with cryptographic techniques, one must only trust the correctness of the design and implementation of the underlying cryptographic primitive. To their advantage, systems built around TEEs can be more flexible, being easier to deploy and configure, and easier to understand, design, and program for programmers who are not experts in applied cryptography. Moreover, the use of hardware-based approaches can offer significant performance benefits, often being orders of magnitudes faster than comparable cryptographic techniques and capable of handling much larger data sets, running at near-native speeds.
Seeking assurance
How does this system address consumer concerns associated with data governance and security?
Providing detailed information
If possible, does the system use edge processing to protect data privacy?
Which techniques are being used to provide data privacy?