And Three Critical Ideas
For each trustworthy AI principle, we outlined the challenges facing its proper implementation and suggested some questions that stakeholders should be able to answer.
In this section, we suggest some possible recommendations to counter these challenges and questions.
We also welcome all other suggestions and recommendations from the industry that would form a better and more useful chain of assurance for trustworthy AI.
Most of the recommendations discussed in this paper fall within the following groups:
Cybersecurity.
Data provenance.
Confidential computing.
Traditional cybersecurity was discussed earlier in section 4.1.1. More information about hardware security can also be found at the PSA Certified website. In this section, we discuss data privacy, confidential computing, and recommendations in more detail.
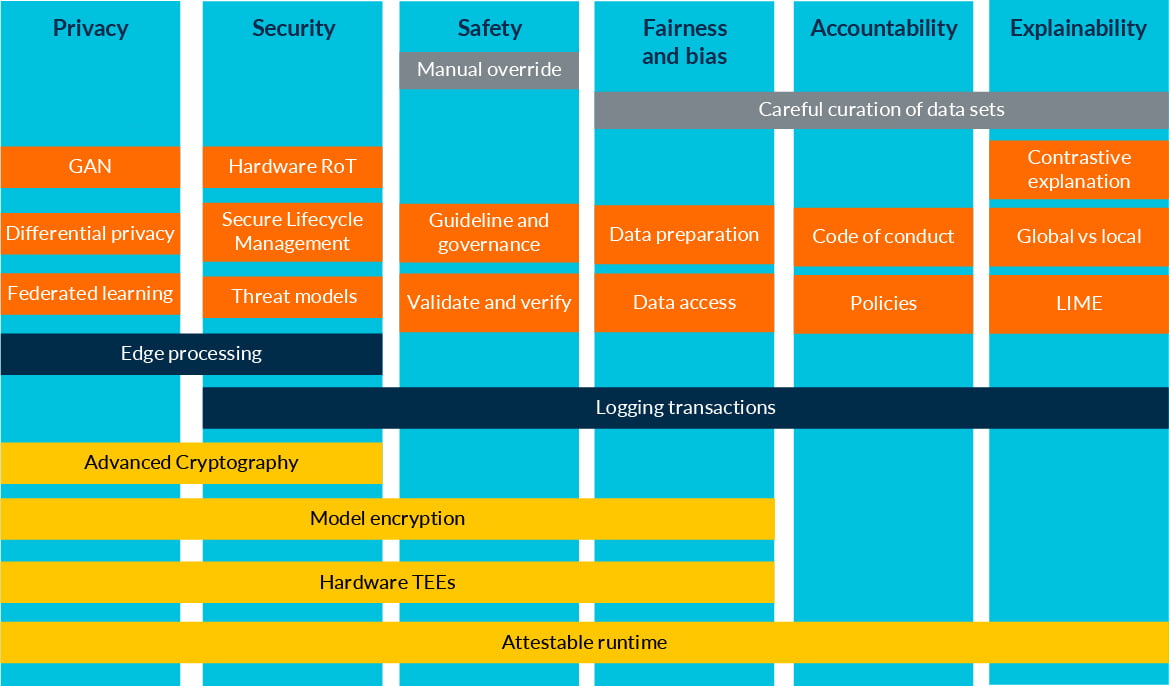
The recommendations we give differ: some are well-recognized solutions (such as hardware TEEs), some require more research (for example, developing unbiased data sets). Recommendations for different principles often overlap — especially for security, safety, and privacy.
Peter Armstrong, cyber subject matter expert, Munich Re Group, discusses the challenges insurers have in quantifying cybersecurity risk.
Trustworthy AI Principles and Recommendations: A Visual Representation
Provenance or lineage metadata describes the modification history of a data set or of the origin and transformation history of data derived from a data set.
Traditionally, pools of data were centralized and assumed to be under the management of trustworthy authorities – dedicated database administrators who restricted who could add data to the data set and in what form.
With such curation, it was reasonable to assume that the data contained within any such data set was consistent, reliable, and had been vetted before being added, with trust in the content of the data set being largely implicit and unstated.33
Today, these assumptions no longer apply for a variety of reasons, but notably, because the rise of the internet has led to an explosion in data creation and synthesis of data sets.
Data is now constantly created and modified, giving rise to potentially huge, decentralized data sets with few guarantees around integrity or form.
Combined with the size increase in modern data sets, this has spurred the development of provenance-tracking techniques.
A significant body of work in this area has been carried out by the database research community, who aimed to answer questions about transformations of data by relating the inputs and outputs of these transformations.34
In particular, the database research community study data to understand the why, how, and where:
Given the output of a data transformation or query, can we identify inputs to the transformation that explain why the output was produced?
Can we track how input data was transformed to demonstrate how a particular output was obtained?
Can we identify which data sets, or which records from a particular data set, contributed to the output of some query or data transformation? That is, can we identify where the origins of inputs that contributed to an output?
Being able to answer these questions is also useful in a machine learning and AI context, especially during the training of machine learning models. For example, by understanding why a model produced an answer, which data sets the model was trained upon, and how the answer was produced, we are better able to debug the model when it produces unfavorable results and to pinpoint sources of bias when they are revealed.
Further, there is a reproducibility crisis in the machine learning community, wherein a large percentage of research papers presenting new machine learning algorithms and techniques cannot be reproduced by third parties. Provenance tracking has therefore been seen as a potential defense against this issue.
The integration of provenance tracking, and provenance metadata, into machine learning pipelines makes it easier to pinpoint exactly which data set was used in an experiment, how it was transformed, and so on, making it easier to replicate.
If machine learning models start to be regularly deployed in regulated domains – such as automotive and medicine – then this reproducibility is vital.
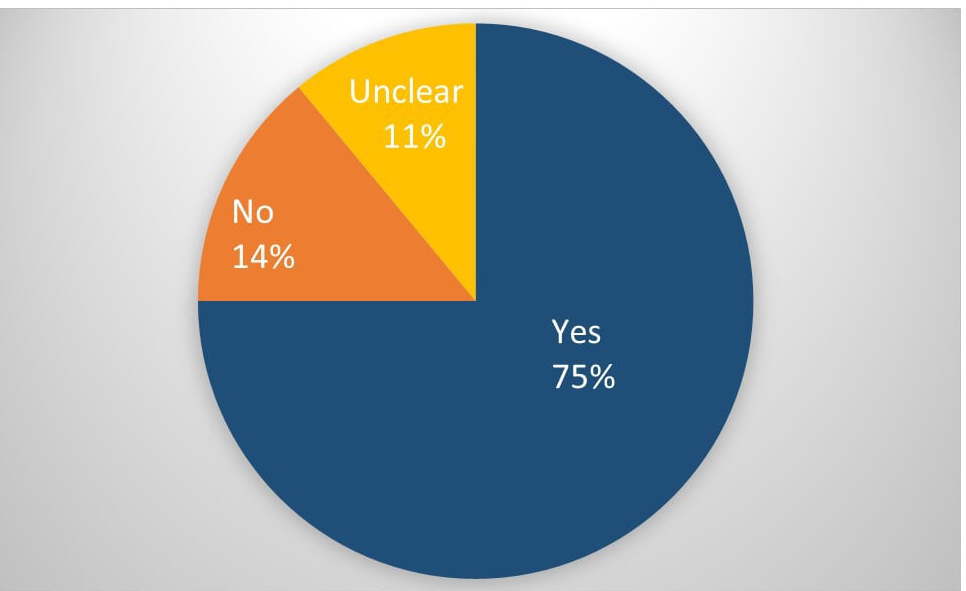
75% of UK and US consumers said there should be more strict regulations on how companies use data to train AI without their knowledge, according to a poll by Audio Analytic. CEO Chris Mitchell discusses the data provenance challenge on Arm Blueprint.
5.1.1 Logging Transactions
To guarantee the quality and integrity of data according to data provenance recommendations, both the integrity of data sets and precisely what has been done with each piece of data, and why, must be logged. This log allows for auditing and potential accident diagnosis in the development, integration, and deployment stages.
Logging transactions also mitigates against membership inference attacks in the deployment stage. Transactions must be logged to detect and deter bad actors in the system.35
Confidential computing refers to a series of techniques where a computation, or inputs to that computation, are protected from untrusted onlookers, who cannot either observe or interfere with the computation.
Cryptographic or hardware-based TEEs may be used to implement these protected computations, or a mixture of the two. In this section, we focus on the use of TEEs in confidential computing.
Notably, many facets of trustworthy AI can be implemented using trusted hardware. For example, TEEs can be used as a mechanism for ensuring data privacy due to the strong confidentiality and integrity guarantees they provide to loaded data and software.
Moreover, TEEs and associated remote attestation procedures can be used as primitives when implementing a provenance chain for data sets.
Several TEE technologies are now available for commodity hardware, including Arm TrustZone,36 Intel’s Software Guard Extensions (SGX),37 AMD’s Secure Encrypted Virtualization (SEV),38 and AWS Nitro Enclaves.39
Arm also has the Realm Management Extensions, part of Arm’s Confidential Compute Architecture (CCA). Some commonalities can be identified:
Strong isolation against a privileged attacker. All the above technologies aim to provide strong integrity and confidentiality guarantees for data and code against a privileged attacker. Arm TrustZone conceptually provides two ‘worlds’ – Secure and Non-Secure – with memory addresses tagged with their originating world.
This insulates code and data in the Secure world from privileged code, even the OS or hypervisor, executing in the Non-Secure world.
Similarly, Intel SGX provides a Secure Enclave which protects code and data from privileged code, including the OS, executing on the same machine.
Additionally, AMD SEV-protected virtual machines, Arm CCA Realms, and Intel SGX Secure Enclaves are backed by integrity-protected encrypted memory, providing some defense, even against physical attackers.
Support for remote attestation. Remote attestation protocols enable a device to authenticate its hardware and software configuration to a third party.
Intuitively, remote attestation protocols allow a skeptical challenger to obtain compelling cryptographic proof – via an attestation token – that a device is configured in a particular way.
For example, to ascertain that a certain piece of software known to the challenger is installed on the device, or the device has known good configuration options set.
Small trusted computing base (TCB). The technologies above aim to reduce the amount of code that is included in the TCB. Notably, this includes moving the ‘rich’ operating system and other privileged system code, such as a hypervisor, out of the TCB.
Numerous startups, and small businesses, are already offering privacy-preserving compute platforms built around TEEs, such as Cosmian40 in France, Decentriq41 in Switzerland, IoTeX in the United States,42 Scalys,43 in the Netherlands, and SCONE44 in Germany.
Established companies, including major cloud providers like Microsoft Azure45 and AWS,46 are also offering access to TEEs, and major financial institutions such as Ant Financial47 in China and JP Morgan Chase in the US are exploring the use of strong isolation technology to protect customer’s data.48
Confidential computing is key to implementing the key areas of security, safety, and privacy in the trustworthy AI chain of assurance.
5.2.1 Hardware-Based Trusted Execution Environments
Using TEEs with attestable properties enables transparency and the reproduction of the compute environment for both development and deployment stages. TEEs can also be used to protect the confidentiality and integrity of sensitive data sets and machine learning models.
When pooling data or using potentially untrusted third-party devices to host a computation, and where advanced cryptographic techniques are inapplicable, we recommend using hardware TEEs to protect computations on user data.
Distributed systems built around TEEs are a pragmatic solution for strong privacy guarantees.
While TEE security and privacy guarantees fall short of pure cryptography, they are widely deployed, efficient, and easier for the average programmer to use.
5.2.2 Edge Processing
Use edge processing where possible to minimize the systemic risk of data pooling. In some distributed system designs, where data is pooled in a central location or shared with untrusted third parties, it may be possible to design the system so that raw data never leaves a user’s device, providing strong data privacy guarantees.
This is the case with federated learning discussed in section 4.3.2.
We recommend that designers of data-intensive distributed systems consider ways to limit the amount of data pooled in centralized services, and how to move more compute onto a user’s device, where possible.
5.2.3 Attestable Runtime
The ability to report, monitor, and correlate potential errors during operation is also a critical component of reliability.
Point-wise reliability, also known as real-time anomaly detection, is an increasingly important approach in the prevention as well as logging of catastrophic failures.
Implementing a computing infrastructure with attestable properties helps reduce potential attacks on models during use.
Remote attestation and runtime measurements enable transparency and more granular monitoring of the operational environment used during both development, as well as deployment stages.
5.2.4 Model Encryption and Decryption
As more models are deployed to the edge, model confidentiality is achieved not only through executing the model in an isolated environment.
Model encryption and decryption on a per-device basis in the deployment stage are becoming increasingly important,49 especially in addressing the model extraction attacks that were mentioned earlier in section 4.1.
5.2.5 Advanced Cryptographic Techniques
Given their strong security and privacy guarantees, use advanced cryptographic techniques for centralized data processing where viable.
In situations that require pooling data in a centralized location, or where computations require more computational power than is available on a user’s device, it may make sense to consider deploying advanced cryptographic techniques, such as Homomorphic Encryption and Secure Multi-party Computations.
While these have long been deemed too inefficient for widespread industrial adoption, many techniques are now reaching a state of maturity and can be deployed profitably in restricted situations.
5.3 Manual Override or Fallback Mechanism
The ability to fail gracefully by having a fallback that can be relied on in the event of failure or unanticipated situations is critically important as a last resort if failure occurs.
Where possible, human intervention should be requested. Otherwise, there needs to be a deterministic form of a rule-based (instead of non-deterministic algorithm) application or component that can take over certain functions, which is in a verified good state. A fallback mechanism must be deterministic in nature, and an attestable signed version of the compute environment, including certified firmware, would normally suffice to ensure reproducibility and the foundation to implement as a fallback mechanism.
5.4 Careful Selection of Data Sets
Engineers and data scientists should keep in mind that machine learning models trained on biased data sets may produce inequitable outcomes once deployed. As a result, they must ensure that sources of potential bias are eliminated from their training data sets, for example by ensuring that the demographics of training data sets used to produce computer vision models are reflective of the wider society.
Coupling carefully considered and curated training data sets with a chain of provenance allows designers to further pinpoint the source of any observed inequity.